Pernahkah Anda bertanya-tanya bagaimana aplikasi peta seperti Google Maps, Uber, atau Gojek dapat menghitung lokasi atau pengemudi terdekat dalam hitungan detik? Rahasianya terletak pada teknik pemrosesan data yang sangat optimal yang mengatasi tantangan kinerja signifikan yang sering dihadapi oleh para profesional di bidang GIS dan data sains. Bekerja dengan set data vektor ekstensif yang berisi jutaan fitur geografis—mulai dari jaringan transportasi global hingga jejak bangunan dan koordinat GPS—dapat membuat aplikasi GIS tradisional seperti QGIS atau ArcGIS Pro menjadi sangat lambat. Program-program ini sering kali kesulitan menangani volume data yang begitu besar, menyebabkan operasi yang bisa memakan waktu berjam-jam, bukan menit.
Kemacetan kinerja ini berasal dari keterbatasan arsitektur platform GIS tradisional, yang tidak dirancang untuk set data geospatial skala besar dan kompleks saat ini. Aplikasi-aplikasi ini sering kali mencoba memproses seluruh set data dalam batas memori atau menggunakan metode pengindeksan spasial yang tidak optimal, sangat menghambat kinerja.
Artikel ini menyajikan alternatif yang kuat, yaitu menggunakan teknik pengindeksan geohash di Python. Geohashing adalah sistem pengindeksan spasial hierarkis yang membagi ruang geografis menjadi sel-sel grid diskrit yang diidentifikasi oleh string alfanumerik. Dengan memanfaatkan metode ini, kita dapat mencapai operasi vektor yang dipercepat secara signifikan seperti analisis kedekatan dan penyaringan spasial. Pendekatan ini menggabungkan fleksibilitas Python dengan struktur data spasial yang dioptimalkan untuk memberikan peningkatan kinerja yang substansial, berpotensi mengurangi waktu pemrosesan dari berjam-jam menjadi hanya beberapa menit atau bahkan detik pada set data skala besar yang sama yang menantang alat GIS tradisional.
Apa itu Geohash?
Geohash adalah sistem pengindeksan spasial hierarkis yang mengkodekan koordinat geografis (lintang dan bujur) menjadi string alfanumerik pendek. Dikembangkan oleh Gustavo Niemeyer pada tahun 2008, geohashing mengubah ruang geografis dua dimensi yang kontinu menjadi representasi grid diskrit, menyediakan solusi elegan untuk pengindeksan, penyimpanan, dan kueri data geografis secara efisien di berbagai skala dan tingkat presisi.
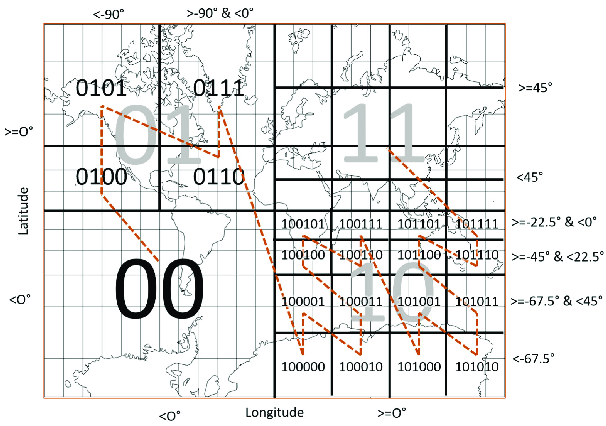
Landasan Teknis Geohash
Pada intinya, geohash mengimplementasikan varian partisi ruang biner melalui proses yang dikenal sebagai pemetaan kurva Z-order (atau pengkodean Morton). Pendekatan matematis ini menyisipkan bit dari nilai lintang dan bujur untuk menciptakan nilai satu dimensi tunggal yang mempertahankan lokalitas spasial. String biner yang dihasilkan kemudian dikodekan menggunakan set karakter base-32 agar mudah dibaca oleh manusia.
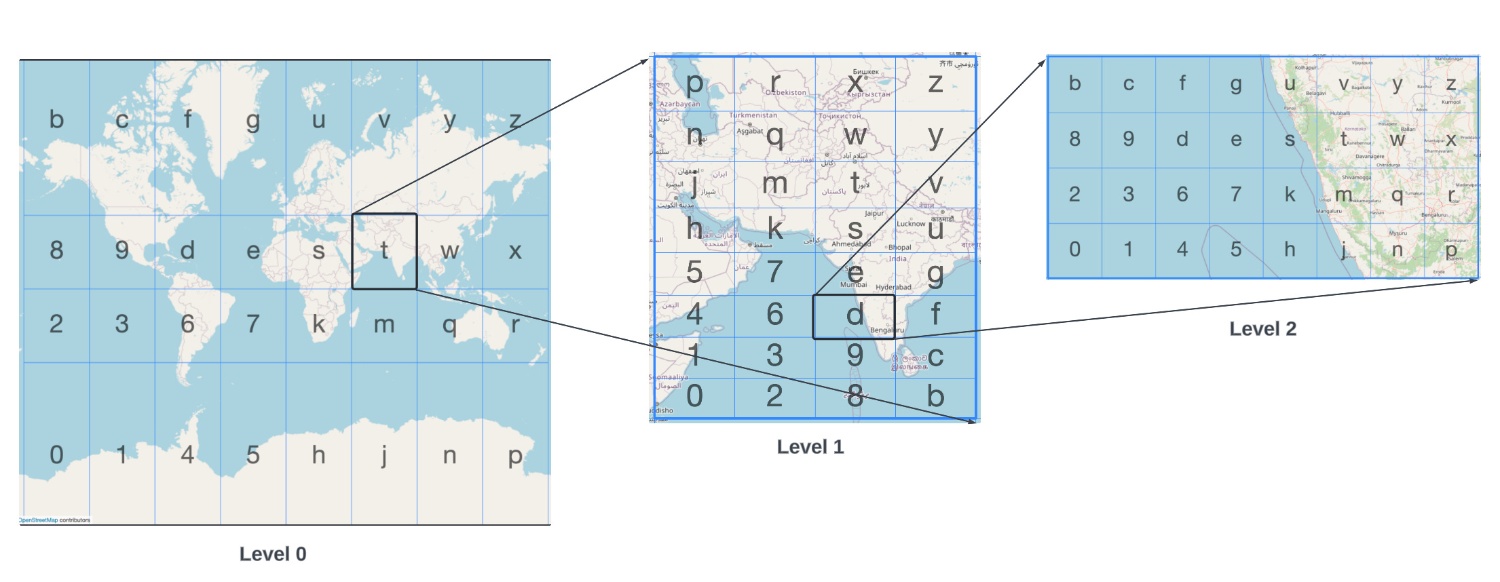
Algoritma geohash secara sistematis membagi dunia melalui proses yang tepat berikut:
-
1.Kotak pembatas awal mencakup seluruh dunia: rentang lintang−90°,90°dan rentang bujur−180°,180°.
-
2.Kotak pembatas ini mengalami subdivisi biner: untuk bit dengan indeks genap, rentang bujur dibagi dua, dan untuk bit dengan indeks ganjil, rentang lintang dibagi dua.
-
3.Setiap subdivisi menghasilkan digit biner: 0 jika titik jatuh di setengah bawah/kiri, 1 jika jatuh di setengah atas/kanan.
-
4.Urutan bit yang dihasilkan dikelompokkan menjadi potongan 5-bit dan dipetakan ke set karakter geohash (0-9 dan b-z, tidak termasuk a, i, l, o).
-
5.Subdivisi rekursif berlanjut hingga presisi yang diinginkan tercapai, dengan setiap karakter tambahan meningkatkan presisi secara eksponensial.
Proses ini menciptakan grid hierarkis di mana setiap sel diidentifikasi secara unik oleh kode geohash-nya. Hubungan presisi mengikuti pola yang konsisten: setiap karakter tambahan dalam geohash meningkatkan presisi sekitar 5 bit, mengurangi ukuran sel dengan faktor 32 (2⁵).
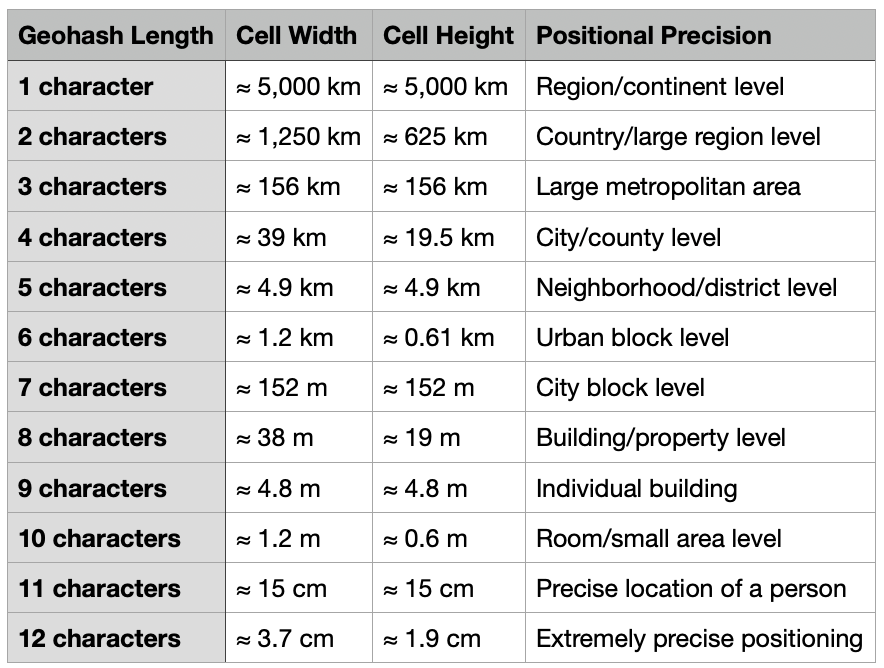
Studi Kasus: Menghitung fasilitas terdekat dengan jarak Euclidean
Studi kasus ini mengeksplorasi penerapan teknik geohashing untuk secara efisien menghitung fasilitas terdekat menggunakan pengukuran jarak Euclidean. Implementasi ini menggunakan set data global OpenStreetMap, secara khusus menargetkan elemen dengan tag , untuk menunjukkan efektivitas pengindeksan spasial untuk pemrosesan data geospatial skala besar.
Komponen kunci dari implementasi ini meliputi:
- Set Data: Data OpenStreetMap global yang berisi jutaan titik fasilitas di seluruh dunia
- Metode Pengindeksan: Geohashing dengan pustaka untuk membuat indeks spasial yang efisien
- Format Penyimpanan: File Parquet yang dipartisi dan diatur oleh prefiks geohash
- Kerangka Kerja Pemrosesan: Dask-GeoPandas untuk komputasi terdistribusi
- Optimalisasi Kueri: Penyaringan kotak pembatas () untuk mengurangi ruang pencarian sebelum perhitungan jarak yang presisi
Implementasi ini mengatasi tantangan komputasi dalam menemukan fasilitas terdekat dari lokasi global mana pun dengan kinerja yang meningkat secara signifikan dibandingkan dengan metode tradisional. Dengan menggabungkan geohashing dengan format penyimpanan yang dioptimalkan dan pemrosesan terdistribusi, sistem ini mencapai hasil yang hampir real-time untuk kueri yang jika tidak, akan membutuhkan sumber daya komputasi yang sangat besar.
Analisis
Saya menggunakan set data Publik Google BigQuery untuk mengambil set data OpenStreetMap, secara khusus mengekstrak catatan yang berisi tag dan tag . Pendekatan ini memungkinkan saya untuk fokus pada titik-titik minat seperti restoran, sekolah, rumah sakit, dan fasilitas publik lainnya di seluruh dunia sambil memastikan setiap lokasi diidentifikasi dengan benar. Untuk melakukan pengambilan data ini, saya mengeksekusi kueri SQL berikut di Google BigQuery:
Saya mengekstrak set data ini dari BigQuery dan menyimpannya dalam dua format: GeoJSON untuk visualisasi dan Apache Parquet untuk pemrosesan yang efisien. Format GeoJSON, meskipun standar untuk pertukaran data geospatial, menghasilkan ukuran file yang jauh lebih besar (2,22 GB) dibandingkan dengan format kolom Parquet. Memuat set data masif ini di perangkat lunak GIS tradisional terbukti menantang—QGIS membutuhkan waktu sekitar 20 menit untuk sepenuhnya merender file GeoJSON di mesin saya, menyoroti keterbatasan kinerja yang ingin kami atasi dengan teknik geohashing. Menghitung jarak dari lokasi referensi tertentu akan sangat memakan sumber daya di QGIS.
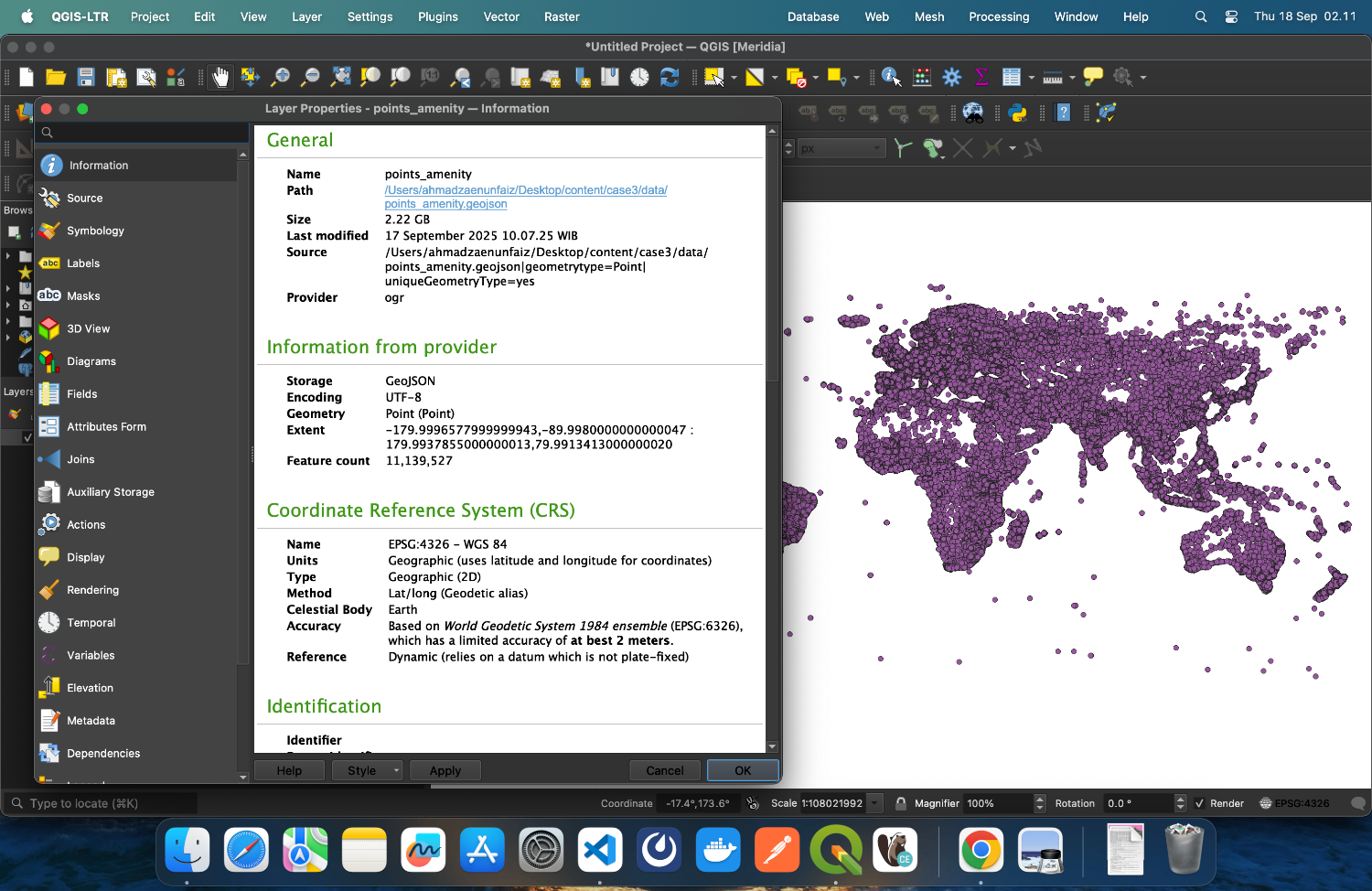
Berdasarkan visualisasi dalam tangkapan layar, set data kami berisi 11.139.527 fitur fasilitas yang dipetakan secara global oleh kontributor OpenStreetMap. Set data titik yang ekstensif ini menyajikan tantangan pemrosesan yang signifikan saat menggunakan aplikasi GIS tradisional. Volume data yang sangat besar membuat operasi spasial seperti pencarian tetangga terdekat dan perhitungan jarak menjadi mahal secara komputasi dan memakan waktu. Pada fase berikutnya dari implementasi kami, kami akan memanfaatkan Dask, pustaka komputasi paralel untuk Python, untuk mempartisi set data masif ini menggunakan pengindeksan geohash. Pendekatan ini akan mendistribusikan beban kerja komputasi di beberapa inti, secara dramatis mengurangi waktu pemrosesan untuk kueri spasial. Dengan menggabungkan partisi spasial berbasis geohash dengan kemampuan komputasi terdistribusi Dask, kita dapat mengubah operasi yang biasanya memakan waktu berjam-jam menjadi proses yang selesai dalam hitungan menit atau bahkan detik.
Membaca file Parquet dengan Dask-Geopandas
Langkah pertama adalah membaca set data besar. Fungsi sangat cerdas, ia tidak mencoba memuat semuanya sekaligus. Sebaliknya, ia membaca data secara "malas", menciptakan DataFrame Dask-Geopandas dengan partisi spasial yang dapat Anda periksa sebelum pekerjaan berat dimulai. Ini memungkinkan saya untuk mendapatkan gambaran tingkat tinggi dari set data Anda, seperti jangkauan geografis setiap partisi, tanpa menghabiskan satu megabyte pun lebih dari yang diperlukan.
Setelah siap untuk menyelami lebih dalam, saya dapat melakukan komputasi untuk mendapatkan gambaran lengkap tentang karakteristik set data. Perintah akan mengungkapkan skala data yang sangat besar—dalam kasus ini, lebih dari 11 juta entri, membutuhkan lebih dari 552 megabyte memori. Ini menunjukkan tantangan, mencoba menjalankan komputasi spasial yang kompleks pada set data sebesar ini dapat dengan mudah menghabiskan sumber daya sistem Anda, terutama saat menghitung hal-hal seperti jarak, yang dapat memakan banyak komputasi.
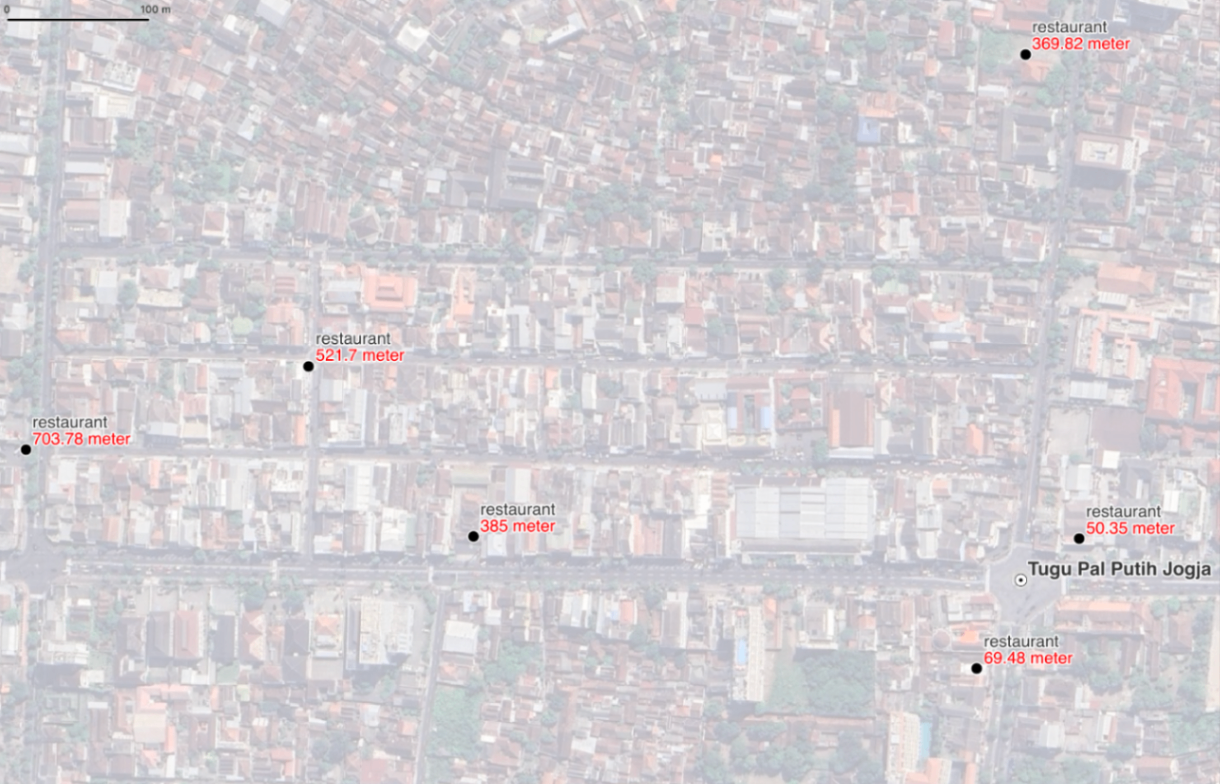
Untuk menemukan fasilitas terdekat, pertama-tama saya perlu mendefinisikan titik-titik minat. Di sini, kami telah menyiapkan GeoDataFrame kecil yang berisi lokasi kunci di Yogyakarta, yaitu Tugu Pal Putih Jogja yang bersejarah. Meskipun ukurannya kecil, GeoDataFrame sederhana ini adalah titik awal untuk kueri kami, menyediakan titik referensi penting untuk menemukan fasilitas di dekatnya.
Tantangan utama sekarang adalah menemukan restoran terdekat dengan salah satu lokasi tersebut di dalam set data masif 11 juta entri. Pencarian brute-force yang lugas akan sangat tidak efisien, memaksa kita untuk menghitung jarak dari setiap lokasi referensi kita ke setiap jutaan fasilitas dalam set data. Pendekatan yang jauh lebih cerdas dan lebih terukur adalah dengan terlebih dahulu menyaring set data kita menggunakan geohash, yang bertindak seperti indeks khusus untuk data geografis. Dengan menggunakan geohash presisi 6, kita dapat secara efisien mempersempit ruang pencarian kita hanya pada fasilitas-fasilitas yang berada dalam area kecil dan spesifik—radius sekitar 1 kilometer—sebelum kita menjalankan perhitungan jarak akhir. Ini secara signifikan mengurangi beban komputasi dan membuat masalah menjadi dapat dikelola.
Menghitung Geohash untuk pencarian dan penyaringan data
Untuk memungkinkan hal ini, kami pertama-tama mendefinisikan dua fungsi pembantu. Fungsi akan mengambil geometri titik dan presisi yang diinginkan dan mengembalikan string geohash yang sesuai. Fungsi adalah kunci untuk optimalisasi kami. Ia mengambil string geohash dan mengembalikan kotak pembatas () yang tepat (sebuah tuple dari batas bujur dan lintang) yang diwakili oleh geohash. Kotak pembatas inilah yang akan kita gunakan untuk menyaring set data masif kita dengan cepat.
Dengan fungsi-fungsi ini di tangan, kita sekarang dapat menerapkannya pada GeoDataFrame kecil kita yang berisi titik minat kita. Dengan menggunakan metode , kita membuat kolom geohash baru dan kolom geohash_bounds yang sesuai untuk setiap lokasi. Langkah ini sangat cepat karena kita hanya beroperasi pada satu titik data. Output menunjukkan persis apa yang telah kita capai: untuk setiap lokasi, kita sekarang memiliki geohash unik dan tuple koordinat yang mendefinisikan kotak pembatasnya yang tepat.
Sekarang kita memiliki batas geohash untuk lokasi kita, kita dapat menggunakannya untuk secara efisien menyaring DataFrame Dask-Geopandas yang masif. Alih-alih melakukan brute-force spatial join yang lambat terhadap seluruh set data 11 juta entri, kita dapat menggunakan kueri untuk memilih hanya data yang berada dalam kotak pembatas yang kecil dan ditargetkan. Pendekatan ini sangat kuat karena Dask-Geopandas dapat membaca hanya partisi yang diperlukan dari file Parquet, menghindari kebutuhan untuk memuat seluruh set data ke dalam memori.
Menghitung jarak Euclidean pada dataframe yang difilter oleh Geohash
Kode di bawah ini pertama-tama menyaring set data untuk hanya menyertakan fasilitas dengan tipe . Kemudian, ia menggunakan filter untuk melakukan yang ditargetkan pada DataFrame Dask. Output akhir menunjukkan betapa efektifnya ini, mengurangi data dari lebih dari 11 juta baris menjadi segelintir lokasi yang dapat dikelola yang benar-benar relevan dengan kueri kita. Ini adalah langkah penting untuk membuat analisis geospatial skala besar menjadi layak pada mesin standar.
Efisiensi pendekatan ini luar biasa, hanya membutuhkan sebagian kecil dari detik untuk menyaring set data masif ini. Langkah logis selanjutnya adalah menghitung jarak yang tepat antara restoran yang ditemukan dan titik referensi kita. Ini dihitung menggunakan perhitungan geodesic ellipsoid dari kerangka kerja , yang memberikan hasil yang sangat akurat.
Unit perhitungan jarak di sini adalah dalam meter, karena kita menggunakan perhitungan geodesic ellipsoid dengan objek dari pustaka , yang ideal untuk pengukuran akurat di permukaan Bumi yang melengkung.
Hasil
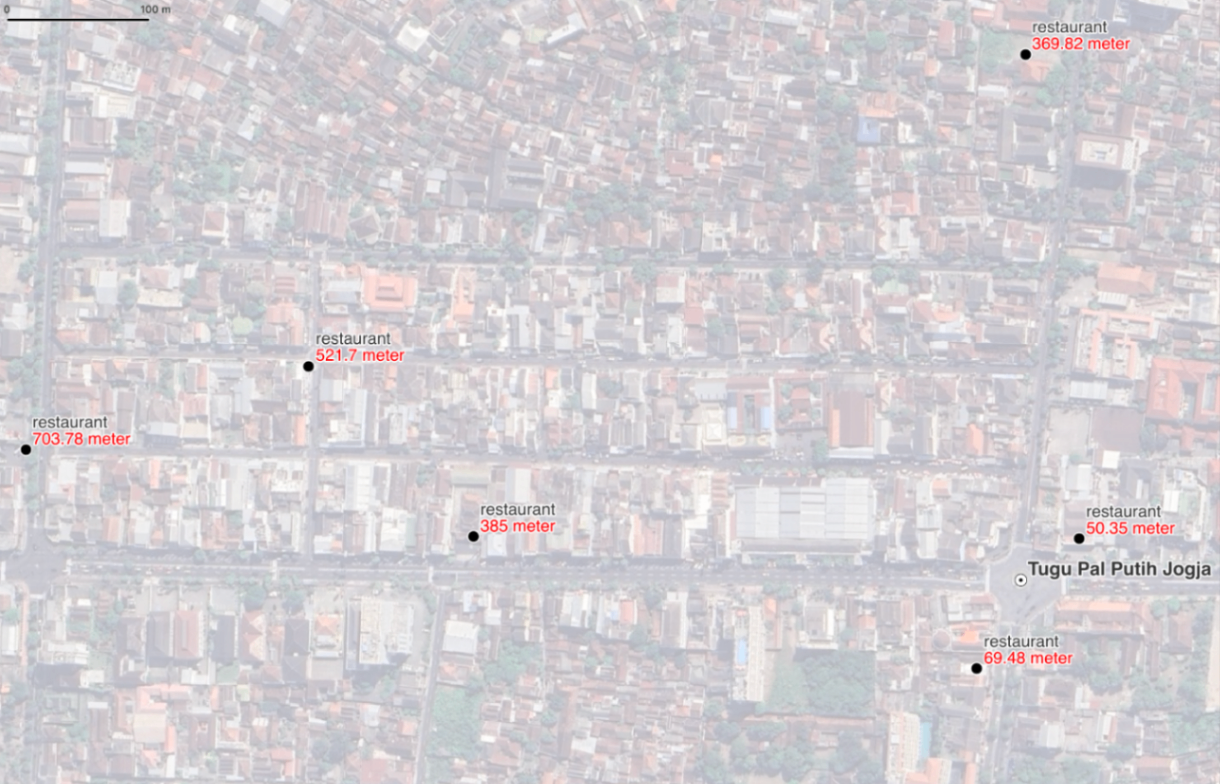
Metodologi yang diuraikan dalam analisis ini berhasil menunjukkan pendekatan yang efisien dan terukur untuk melakukan kueri spasial pada set data geospatial skala besar. Dengan secara strategis menggabungkan kemampuan komputasi paralel Dask dengan pengindeksan spasial berbasis geohash, kita mengubah operasi yang biasanya memakan waktu menjadi sangat performant. Perintah ddf.comenegaskan tantangan: set data dengan lebih dari 11 juta entri yang hampir tidak mungkin diproses dengan pendekatan brute-force. Namun, langkah-langkah selanjutnya membuktikan efektivitas strategi kami.
Filter geohash berfungsi sebagai langkah pendahuluan yang kuat, secara drastis mengurangi ruang pencarian dari jutaan fitur menjadi segelintir yang dapat dikelola. Untuk lokasi Tugu Pal Putih Jogja, berhasil menyaring set data menjadi hanya 6 restoran relevan di dalam area yang ditargetkan. Ini menunjukkan pengurangan beban komputasi yang signifikan, memungkinkan perhitungan jarak yang lebih presisi selanjutnya dieksekusi dengan kecepatan dan akurasi.
Langkah terakhir, memanfaatkan pustaka , memberikan pengukuran jarak yang tepat dan real-world untuk setiap lokasi yang difilter, mengkonfirmasi bahwa restoran terdekat dengan Tugu Pal Putih Jogja berjarak hanya 50.35 meter. Pendekatan komprehensif ini membuktikan bahwa dengan memanfaatkan pustaka modern dan teknik pengindeksan yang cerdas, kita dapat mengatasi masalah geospatial skala besar secara efisien, akurat, dan tanpa membebani sumber daya sistem, meniru kinerja yang terlihat pada aplikasi pemetaan dan pengiriman modern.
Kesimpulan
Geohashing mewakili pendekatan transformatif untuk memproses set data geospatial besar, mengatasi keterbatasan fundamental platform GIS tradisional melalui keanggunan matematis dan efisiensi komputasi. Dengan mengubah hubungan spasial dua dimensi yang kompleks menjadi string atau bilangan bulat satu dimensi yang dapat dikelola, geohashing memungkinkan peningkatan kinerja orders-of-magnitude untuk banyak operasi geospatial umum.
Meskipun bukan solusi universal untuk semua tantangan geospatial, geohashing menyediakan alat yang sangat kuat untuk penyaringan awal dan pengorganisasian set data vektor besar, secara dramatis mengurangi beban komputasi dari operasi geometris presisi selanjutnya. Bagi para ilmuwan data dan profesional GIS yang bekerja dengan set data geografis ekstensif, mengimplementasikan pipeline pemrosesan berbasis geohash dapat membuka kemungkinan analitis baru dan mengubah masalah spasial yang sebelumnya tidak dapat diatasi menjadi alur kerja yang dapat dikelola.

![[GEODATA] Tutupan Lahan Indonesia](https://mapidstorage.s3.amazonaws.com/general_image/mapidseeit/1684312961161_COVER%20GEODATA_%20Tutupan%20Lahan.png)
![[GEODATA] Status Ekonomi dan Sosial (SES) Indonesia](https://mapidstorage.s3.amazonaws.com/general_image/mapidseeit/1693454652933_20230831-085941.jpg.jpeg)
![[GEODATA] Point of Interest (POI)](https://mapidstorage.s3-ap-southeast-1.amazonaws.com/foto_doc/mapidseeit/doc_1648452337_d8074cde-5aef-4820-88ba-b6cc500a7e04.jpeg)